
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- AI
- YarinGal
- VAE
- 리눅스
- pandas
- 텍스트마이닝
- 파이썬
- 텍스트분석
- Graph
- PYTHON
- 코딩테스트
- uncertainty
- 논문리뷰
- 빅데이터
- 우분투
- 베이지안
- GNN
- R
- 강화학습
- selenium
- DATA
- 백준
- 알고리즘
- 데이터분석
- bayesian
- Crawling
- 불확실성
- 크롤링
- dropout
- pytorch
- Today
- Total
끄적거림
[Tips] 컴프리헨션(Comprehension), 이터레이터(Iterator), 제너레이터(Generator) 본문
R을 많이 사용하던 사람으로써 python의 컴프리헨션(Comprehension), 이터레이터(Iterator), 제너레이터(Generator)와 같은 개념들이 다소 생소했다.
먼저 각 개념부터 알아보자.
컴프리헨션(Comprehension)
: 주로 리스트 타입에서 많이 사용하기 때문에 리스트 컴프리헨션이라고도 한다.
반복되는 작업을 간결한 표시로 동작하는 것을 List Comprehension이라고 한다. 예를 보며 확인해보자.
# 1. Comprehension
a = [x**2 for x in range(5)]
print(a)
# 2. Normal for loop
a = []
for i in range(5):
a.append(i**2)
print(a)1번 코드는 컴프리헨션을 이용한 반복 작업이고, 2번 코드는 일반적인 for loop을 이용한 반복작업이다. 둘의 결과는 동일하다.
보기에 가독성 부분에서 매우 우수한 것을 알 수 있다. 그렇다면 퍼포먼스 부분에서는?
from timeit import timeit, Timer
def Comp_func():
t = [x**2 for x in range(500)]
return(t)
def forLoop_func():
t = []
for i in range(500):
t.append(i**2)
return(t)
Loop_timer = Timer("""forLoop_func()""", """from __main__ import forLoop_func""")
Comp_timer = Timer("""Comp_func()""", """from __main__ import Comp_func""")
print("Comprehension : ", Loop_timer.timeit(10000), "s")
print("for Loop : ", Comp_timer.timeit(10000), "s")
# Comprehension : 1.1566042000000039 s
# for Loop : 0.9301347999999905 s간단한 함수를 만들어 이에 대한 퍼포먼스를 고려해보았다. 10000번의 반복 작업에 있어 어느 것이 효율적인지 살펴보았다.
위의 코드처럼 그 결과는 의외로 for문을 이용한 반복문이 더 빨랐다는 것을 알 수 있었다.
그럼 benchmark를 집행해보자.
원래 벤치마킹하는 툴과 다른 코드가 있을테지만 본인은 그냥 간단한 코딩으로 살펴보기로 한다.
res = [[Loop_timer.timeit(n), Comp_timer.timeit(n)] for n in [10,50,100, 50,1000,5000,10000, 50000, 100000]]
res = pd.DataFrame(res)
print(res)
# 0 1
# 0 0.001153 0.000946
# 1 0.005980 0.005058
# 2 0.011719 0.009501
# 3 0.006248 0.004811
# 4 0.115810 0.093305
# 5 0.577613 0.472219
# 6 1.154362 0.937352
# 7 5.807373 4.657995
# 8 12.804847 9.510663import matplotlib as mpl
import matplotlib.pylab as plt
import pandas as pd
plt.plot(res)
plt.legend(["Comp", "Loop"])
plt.show()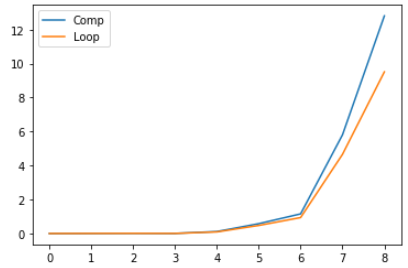
확인 결과, for문을 이용한 반복문이 더 빠른 것을 알 수 있다. 하지만 그 차이는 미미하다.(물론 작업량이 많을수록 그 차이는 커진다.)
성능상으로 크게 차이가 나지 않을 뿐더러, 가독성면과 간결성면에서 컴프리핸션이 더 좋아보이긴 한다.
간단한 반복문은 앞으로 컴프리핸션을 이용해보자.
하지만 큰 작업이 있을 경우, Comprehension은 지양하자.
여기서 주의 사항이 있다!
list Comprehension에서 두 개 이상의 표현을 사용하지는 말자!
컴프리핸션의 장점이었던 간결성과 가독성이 낮아지는 효과와 함께 퍼포먼스적으로도 안좋아 질 수 있다.
여기서 팁을 하나 주자면 조건을 걸 수 있다. 바로 이렇게
test = [print(n) for n in range(100) if n%2 == 1]
이터레이터(Iterator)
이터레이터는 간단히 생각해서 반복 가능한 객체를 의미한다.
제너레이터(Generator)
'Python' 카테고리의 다른 글
| [API]기상청 api로 데이터 가져오기 2 in Python(feat. 동네예보 - 초단기실황) (1) | 2020.02.29 |
|---|---|
| [API] 영화진흥위원회 제공 박스오피스 API 사용 (0) | 2020.02.28 |
| [Tips] byte, str 타입 오류(feat. TypeError: write() argument must be str, not bytes) (0) | 2020.02.21 |
| [API]네이버데이터랩 api로 데이터 가져오기 in Python (0) | 2020.02.19 |
| [API]기상청 api로 데이터 가져오기 in Python(feat. ASOS 종관기상관측) (0) | 2020.02.18 |


