
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
- pytorch
- Crawling
- bayesian
- GNN
- selenium
- R
- PYTHON
- pandas
- dropout
- AI
- 리눅스
- 크롤링
- uncertainty
- 데이터분석
- 우분투
- 백준
- DATA
- VAE
- 텍스트마이닝
- 텍스트분석
- Graph
- 알고리즘
- 강화학습
- 파이썬
- 논문리뷰
- YarinGal
- 빅데이터
- 코딩테스트
- 베이지안
- 불확실성
- Today
- Total
끄적거림
[베이지안/pytorch] Bayesian Neural Network 코딩해보기 by torchbnn package 본문
[베이지안/pytorch] Bayesian Neural Network 코딩해보기 by torchbnn package
Signing 2021. 2. 4. 17:23참고자료: github.com/Harry24k/bayesian-neural-network-pytorch
Harry24k/bayesian-neural-network-pytorch
Bayesian Neural Network For Pytorch. Contribute to Harry24k/bayesian-neural-network-pytorch development by creating an account on GitHub.
github.com
베이지안 딥러닝에 대해서 그동안 2개의 논문을 통해 알아보았는데, 이번에는 실제로 코딩을 어떻게 하는지 알아보고자 한다.
내가 주로 공부하는 것은 pytorch이기 때문에 다른 프레임워크인 tensorflow을 통한 코딩은 다루지 않도록 하겠다.
찾아본 바로는 pytorch에서 BNN 모델링을 진행할 때, 도움을 주는 패키지가 대략 2개 정도 있다.
하나는 torchbnn, 다른 하나는 blitz 이다.
일단은 torchbnn부터 보겠다.
참고: bayesian-neural-network-pytorch.readthedocs.io/_/downloads/en/latest/pdf/
Regression Task
1. package 설치
!pip install torchbnn해당 패키지를 설치하는 방법은 여러가지가 있겠으나, jupyter notebook 환경이라면 위의 코드처럼 앞에 !를 붙여주면 된다.
일반 cmd창에서는 ! 빼고 위의 코드를 돌려주면 된다.
2. package
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
import torchbnn as bnn
import matplotlib.pyplot as plt
%matplotlib inline간단한 모델을 만들것이기 때문에 위의 패키지들만으로도 충분하다.
3. Generate Data
x = torch.linspace(-2, 2, 500)
y = x.pow(3) - x.pow(2) + 3*torch.rand(x.size())
x = torch.unsqueeze(x, dim=1)
y = torch.unsqueeze(y, dim=1)
plt.scatter(x.data.numpy(), y.data.numpy())
plt.show()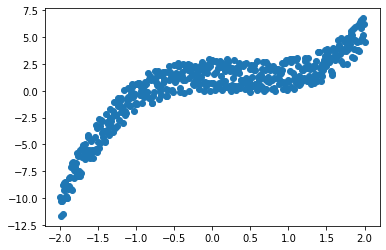
y = x^3 - x^2 + 3*e 의 식을 가지고 데이터를 생성한 것이다.
일반 다항식에 noise(=위식에서 e)를 더한 것이다.
4. Define Model
model = nn.Sequential(
bnn.BayesLinear(prior_mu=0, prior_sigma=0.1, in_features=1, out_features=100),
nn.ReLU(),
bnn.BayesLinear(prior_mu=0, prior_sigma=0.1, in_features=100, out_features=1),
)
mse_loss = nn.MSELoss()
# loss for calculating KL-divergence of BNN model
kl_loss = bnn.BKLLoss(reduction='mean', last_layer_only=False)
kl_weight = 0.01
optimizer = optim.Adam(model.parameters(), lr=0.01)모델은 매우 간단한 모델을 만들었다.
single layer에 node의 수가 100개인 Single Layer NN model이다.
단, 여기서 weight들은 어떤 고정값을 갖는 것이 아니라 BNN이기 때문에 분포를 띄고 있어야하므로 bnn의 BayesLinear함수를 사용해야한다.
prior_mu와 prior_sigma는 분포를 이미 gaussian으로 설정했기 때문에 분포를 정의하기 위한 parameter이다.
그리고 중간에 kl_loss에 대해서 언급을 하고 있는데, kl_loss는 KL-Divergence에 대한 loss인 것이다.
BKLLoss함수에서의 parameter는 아래와 같다.
- reduction: Specifies the reduction to apply to the output
- 'mean'
- 'sum'
- last_layer_only: True for return only the last layer's KL-divergence
5. Train Model
kl_weight = 0.1
for step in range(3000):
pre = model(x)
mse = mse_loss(pre, y)
kl = kl_loss(model)
cost = mse + kl_weight*kl
optimizer.zero_grad()
cost.backward()
optimizer.step()
print('- MSE : %2.2f, KL : %2.2f' % (mse.item(), kl.item()))
# - MSE : 0.93, KL : 5.36total cost function을 MSE loss에 일정 weight를 곱한 KL-divergence의 값을 더한 값이다.
6. Test Model
x_test = torch.linspace(-2, 2, 500)
y_test = x_test.pow(3) - x_test.pow(2) + 3*torch.rand(x_test.size())
x_test = torch.unsqueeze(x_test, dim=1)
y_test = torch.unsqueeze(y_test, dim=1)plt.xlabel(r'$x$')
plt.ylabel(r'$y$')
plt.scatter(x_test.data.numpy(), y_test.data.numpy(), color='k', s=2)
y_predict = model(x_test)
plt.plot(x_test.data.numpy(), y_predict.data.numpy(), 'r-', linewidth=2, label='First Prediction')
y_predict = model(x_test)
plt.plot(x_test.data.numpy(), y_predict.data.numpy(), 'b-', linewidth=2, label='Second Prediction')
y_predict = model(x_test)
plt.plot(x_test.data.numpy(), y_predict.data.numpy(), 'g-', linewidth=2, label='Third Prediction')
plt.legend()
plt.show()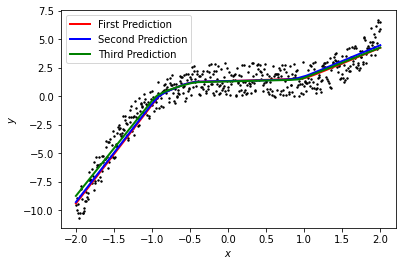
이제 학습을 완료한 후, 모델에 fitting한 결과를 나타낸 것이다.
보면 알겠지만, 3번의 output을 생성하여 fitting한 결과인데, 세 번 각기 다른 모델인 것을 알 수 있다.
아주 근소한 차이로 다른 모델인 것이다.
BNN은 weight가 분포로써 존재하기 때문에 그렇다.
같은 input이라 할지라도 매번 결과가 다르게 나온다.
Classfication Task
분류 문제도 위의 회귀 문제와 거의 동일하게 진행이 된다.
따라서 각 단계별 언급은 스킵하겠다.
1. Load Data
iris = datasets.load_iris()
X = iris.data
Y = iris.target
x = torch.from_numpy(X).float()
y = torch.from_numpy(Y).float().long()
x.shape, y.shape2. Define Model
model = nn.Sequential(
bnn.BayesLinear(prior_mu=0, prior_sigma=0.1, in_features=4, out_features=100),
nn.ReLU(),
bnn.BayesLinear(prior_mu=0, prior_sigma=0.1, in_features=100, out_features=3),
)
ce_loss = nn.CrossEntropyLoss()
kl_loss = bnn.BKLLoss(reduction='mean', last_layer_only=False)
optimizer = optim.Adam(model.parameters(), lr=0.01)3. Train Model
kl_weight = 0.1
for step in range(3000):
pre = model(x)
ce = ce_loss(pre, y)
kl = kl_loss(model)
cost = ce + kl_weight*kl
optimizer.zero_grad()
cost.backward()
optimizer.step()
_, predicted = torch.max(pre.data, 1)
total = y.size(0)
correct = (predicted == y).sum()
print('Acc: %f %%' %(100*float(correct)/total))
print('CE : %2.2f, KL: %2.2f' % (ce.item(), kl.item()))4. Test Model
def draw_plot(predicted):
fig = plt.figure(figsize=(16,5))
ax1 = fig.add_subplot(1,2,1)
ax2 = fig.add_subplot(1,2,2)
z1_plot = ax1.scatter(X[:, 0], X[:, 1], c=Y)
z2_plot = ax2.scatter(X[:, 0], X[:, 1], c=predicted)
plt.colorbar(z1_plot, ax=ax1)
plt.colorbar(z2_plot, ax=ax2)
ax1.set_title('REAL')
ax2.set_title('PREDICT')
plt.show()pre = model(x)
_, predicted = torch.max(pre.data, 1)
draw_plot(predicted)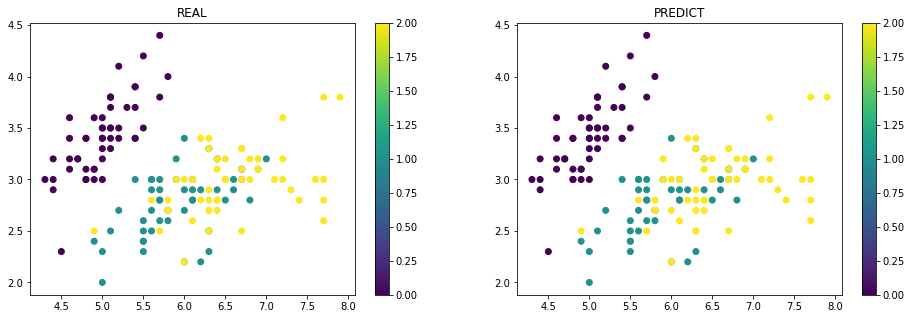
blitz package
github.com/piEsposito/blitz-bayesian-deep-learning#A-simple-example-for-regression
piEsposito/blitz-bayesian-deep-learning
A simple and extensible library to create Bayesian Neural Network layers on PyTorch. - piEsposito/blitz-bayesian-deep-learning
github.com
ichi.pro/ko/blitz-pytorch-yong-beijian-singyeongmang-laibeuleoli-144008534365895
BLiTZ — PyTorch 용 베이지안 신경망 라이브러리
Blitz — Torch Zoo의 Bayesian Layers는 PyTorch 위에 베이지안 신경망 계층을 생성하기위한 간단하고 확장 가능한 라이브러리입니다. 이것은 Deep Bayesian Learning을위한 라이브러리 사용에 관한 글입니다.
ichi.pro
'개인 공부 정리 > Bayesian' 카테고리의 다른 글
| [논문 리뷰] Bayesian Reinforcement Learning: A Survey - 1.Introduction (0) | 2021.06.25 |
|---|---|
| [논문 실습] Dropout as a Bayesian Approximation 실습 코드 - pytorch ver (2) | 2021.04.20 |
| [논문 리뷰] Dropout as a Bayesian Approximation 설명 - 7.Conclusion (1) | 2021.02.02 |
| [논문 리뷰] Dropout as a Bayesian Approximation 설명 - 6.Experiment (1) | 2021.02.01 |
| [논문 리뷰] Dropout as a Bayesian Approximation 설명 - 5.Methodolgy (4) | 2021.02.01 |


