
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 불확실성
- 크롤링
- dropout
- 빅데이터
- 우분투
- selenium
- Crawling
- 데이터분석
- DATA
- 리눅스
- AI
- GNN
- 알고리즘
- 베이지안
- 텍스트분석
- PYTHON
- uncertainty
- 텍스트마이닝
- YarinGal
- 코딩테스트
- 강화학습
- pandas
- bayesian
- VAE
- R
- 백준
- pytorch
- 논문리뷰
- Graph
- 파이썬
- Today
- Total
끄적거림
[논문 리뷰] How Good is the Bayes Posterior in Deep Neural Networks Really? 본문
[논문 리뷰] How Good is the Bayes Posterior in Deep Neural Networks Really?
Signing 2021. 10. 26. 22:27[논문 소개] Cold Posterior Effect 관련 논문들
[논문 소개] Cold Posterior Effect 관련 논문들
베이지안 관련 최신 논문들을 찾다보니 또 하나의 새로운 개념을 알게 되었다. Cold Posterior Effect(이하 CPE.)라는 개념인데 아직 계속해서 공부중이고, 이 것을 파다보니 연관된 다른 논문들이 많이
signing.tistory.com
cold posterior를 가장 핵심으로 다루고 있는 논문인듯 하다.
논문 페이지가 꽤 많고(33페이지), 다른 논문들이 위 논문을 많이 refer했다.
어떤 논문에서는 해당 논문에 대해 문제를 제기하기도 했지만, 그래도 무엇 때문에 문제가 발생하는지, 정확한 개념이 무엇인지 확인해봐야겠다는 생각으로 본 논문을 간단히 짚고 넘어가고자 한다.
1. Introduction

데이터가 주어지고, 그에 대한 probabilistic model p(y|x, theta), 즉, likelihood가 위와 같다.
뒤에 오메가 항은 regularizer이다.
흔히 위 식을 최적화할 때는 SGD 등과 같은 방법론을 사용한다.
1.1 Bayesian Deep Learning
1.1.1
베이지안 딥러닝에서는 하나의 model 만으로 optimize를 하지 않는다.
single parameter를 갖지 않는다는 의미이다.
즉, parameter가 deterministic하지 않다는 뜻이며, parameter가 분포를 이루고 있다는 뜻이다.
어찌되었든 우리는 가능한 모든 likely model을 찾고싶어한다.
1.1.2
그러기 위해서는 parameter에 대한 posterior distribution(이하 dist.)를 알아야하는데, 아래의 식과 T라는 temperature를 사용한다.

1.1.3
쌩뚱맞게 (2)번 식이 어디서 나왔냐면, (1)의 식에서 오메가 항(regularizer term)을 아래와 같이 설정하고, 1/n을 곱해주면 된다.

1.1.4
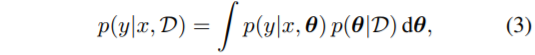
위의 posterior predictive(다른 말로 Bayes ensemble) 식을 구하는 것은 매우 어려운 일이다.
그래서 보통은 아래 식처럼 sample approximation 기법을 활용하여 적분을 sigma로 구한다.
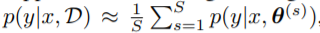
이때, parameter 집합인 theta는 posterior dist.에서 sampling하여 진행한다.
1.1.5
기존의 posterior(T=1일 때)로 task를 수행하기에는 성능이 잘 나오지 않았다.
그러나 T < 1 인 temperature로 cooling한 posterior를 사용하게 되면 prediction 성능을 향상시킬 수 있다고 한다.
Cold Posterior : holdout data에서 모든 temperized된 posterior들 중 가장 predictive 성능이 좋았던 posterior은 T<1인 Temperated posterior였다.
1.2 Why should Bayes (T=1) be Better?
1.2.1
Ensemble model(Bayes posterior) 방법론이 왜 일반적인 single parameter model 보다 더 성능이 좋을까?
그에 대한 이유는 3가지가 있다.
① posterior predictive 방법론으로 예측 성능을 내는 여러 model들이 likelihood에 기초한 가장 그럴싸한 point estimator를 도출한다.
② 실제 practive에서 classic한 통계모델이기 때문에 robustness가 좋다.
③ Model average 효과가 있다.
1.2.2
지난 기간동안 베이지안 딥러닝은 꽤나 바람직하게 연구되어 왔었다.
1.2.3
본 논문의 contribution은 아래와 같다.
- CIFAR-10에서의 ResNet-20 model과 IMDB에서 CNN-LSTM, 두 모델과 dataset에서 Bayes posterior predictive는 성능이 좋지 못했다.
심지어 SGD보다도 못했다. - 그래서 이를 설명할 수 있는 가설을 제시하고 검토했다.
- SG-MCMC를 이용한 approximation과 성능향상
2. Cold Posterior Perform Better
2.1 Deep Learning Model : ResNet-20 and LSTM
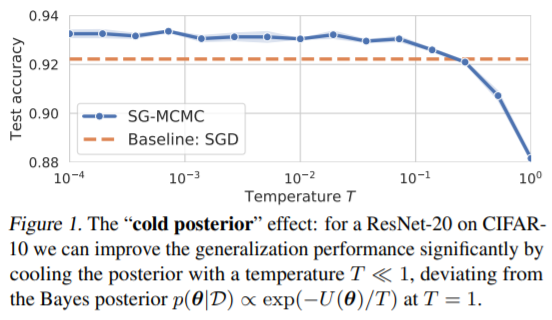
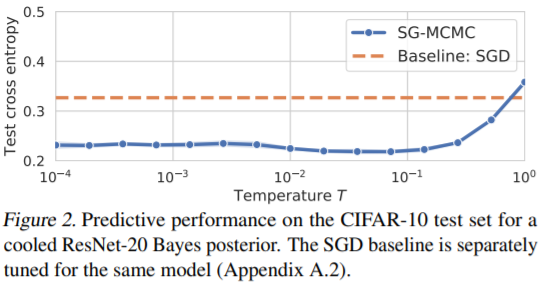
2.1.1
(3)번 식을 이용한 Bayes prediction에서 test cross-entropy와 test accuracy를 나타낸 그림이다.
2.1.2
Cold Posterior Effect(이하 C.P.E.)
CIFAR-10 데이터셋에서 ResNet-20 모델을 학습시켰을 때, temperature T가 1보다 작은 cooling posterior의 성능이 기존의 posterior(T=1일 때) 눈에 띄게 향상되었다는 것을 확인 할 수 있다.
특히 T < 0.1일때 효과적으로 나타났다.
2.1.3
(Appendix G 참고) uncertainty를 측정하는 지표인 Brier score와 ECE(expected calibration error)도 좋아졌다고 한다.
2.1.3 - Appendix G. Cold Posterior improve uncertainty metrics.
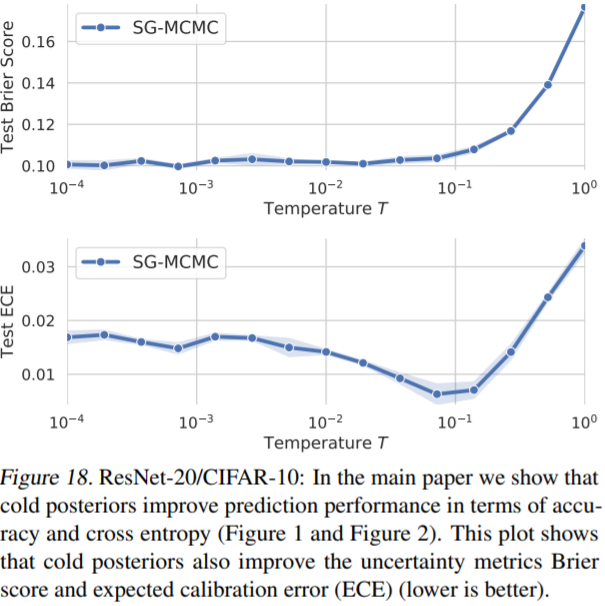
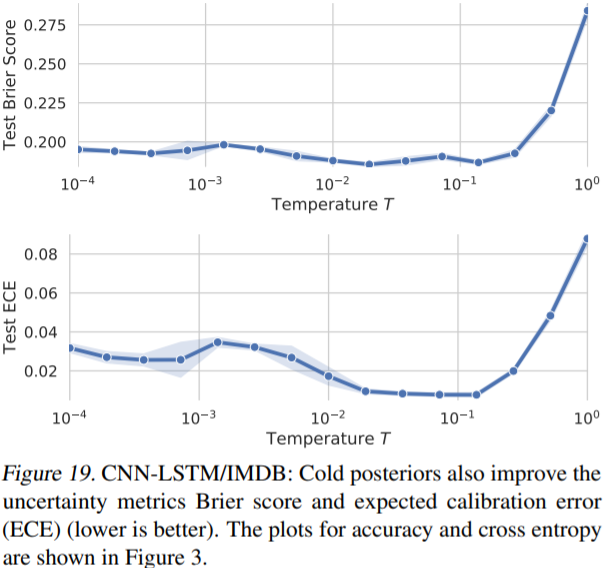
Figure 18, 19는 ResNet-20과 CNN_LSTM 모델에 대해 cold posterior가 uncertainty metric인 Brier score와 ECE도 향상시켰다는 결과이다.
2.2. Why is a Temperature of T < 1 a Problem?
cold posterior가 갖는 문제점이 2개가 있다고 한다.
- posterior를 더 sharpening하게 했다는 것
- 1/T라는 factor로 overcounting된 data를 설명할 수 있기 때문
- prior도 rescaling했기 때문
- T=1이면 True Bayes posterior와 같고, T < 1에 대한 성능향상은 prior, likelihood, inference procedure과 함께 더 깊고, 잠재적인 문제를 해결할 수 있다는 것
2.3. Confirmation from the Literature
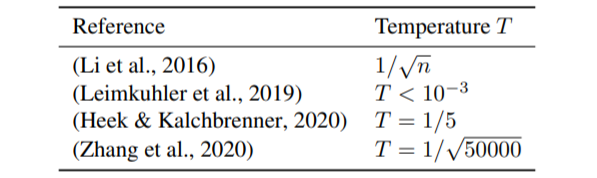
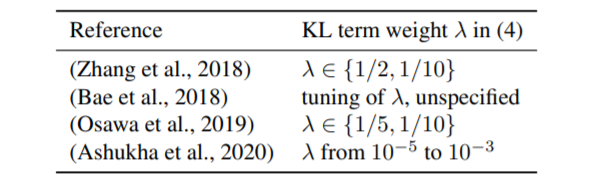
T<1를 하는 것은 사실 cold posterior가 처음이 아니다.
위 그림 외에도 posterior를 위한 variational inference(이하 V.I.)에서도 사용되었다.
V.I.에서 posterior를 구할 때, ELBO를 maximize하는데, KL-d term에 lambda < 1라는 factor를 주었더니 predictive 성능이 올라갔다는 연구결과도 있다.
위 연구 리스트들로 tempering하는게 좋다는 기록과 연구가 남겨졌고, T=1인 일반적인 posterior를 갖는 BNN에서 성능이 좋다는 연구는 사실 보기 힘들다.
3. Bayesian Deep Learning in Practice
이번 절에서는 본 연구의 실험이 BNN posterior가 얼마나 효율적이고 정확했는지를 밝히고 있다.
* 이번 절에서는 아래에 대한 back-ground가 있어야한다.
- Langevin Dynamics
- SG-MCMC
4. (수정중) Inference: Is it Accurate?
일단 일반적인 Bayes posterior와 cold posterior는 둘 다 계산할 수 없다.
한 편, SG-MCMC는 mini-batch noise를 추가로 처리해야하고, 유한 표본에서 근사치만 생성한다.
종합하면, inference 정확도가 낮은데 C.P.E.가 발생할 수 있을까? 하는 의문이 들 수 있다.
이로부터 발생하는 4가지 가설을 본 논문에서 제시한다.
- Inaccurate SDE Simulation
- Biased SG-MCMC
- Minibatch Noise
- Bias-variance Tradeoff
자세한 것은 나중에 추가하기로 하겠다.
5. Why could the Bayes Posterior be Poor?
5.1. Problems in the likelihood function
5.1.1
BNN에서도 기존에 사용되던 likelihood function이 사용되기 때문에 SGD를 사용한다.
따라서 같은 likelihood function이 SGD로 기존에 잘 작동되기 때문에 C.P.E.를 설명할 가능성은 낮은 것으로 보인다.
그러나 요즘 DL 모델들은 많은 data augmentation, dropout, batch-normalization 등 다양한 테크닉들을 사용하지만 진정한 likelihood fuction이 아니다.
5.1.2
그래서 나온 것이 Dirty-likelihood 가설이다.
data augmentation, dropout, batch-normalization 등의 likelihood principal을 위반하는 DL practice는 bayes posterior에서 deviation(편향, 문제라고 해석?)을 일으킨다.
5.2. Problems with the Prior p(theta)?
5.2.1
귿오안 Normal distribution prior를 사용해왔는데 과연 이것이 괜찮은 prior인가?
5.2.2
기존에 알고 있는 모델 아키텍쳐라면 simple prior로 충분하고 그럴듯하지만, 신중해야한다.
별거 아니라고 여겨졌던 것이 사실 매우 중요했던 사례가 많기 때문이다.
5.2.3
그래서 Bad prior 가설이 나왔다.
BNN parameter에 사용되는 prior는 적절하지 않다는 가설이다.
의도한 정보를 제공하지 않고, 모델의 depth와 capacity가 증가함에 따라 이런 단점이 증폭한다.
