
반응형
250x250
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- AI
- 텍스트분석
- 텍스트마이닝
- DATA
- 강화학습
- 불확실성
- VAE
- 데이터분석
- 파이썬
- PYTHON
- Crawling
- pytorch
- YarinGal
- 알고리즘
- 베이지안
- selenium
- 리눅스
- Graph
- uncertainty
- bayesian
- 논문리뷰
- 코딩테스트
- 백준
- 우분투
- 크롤링
- 빅데이터
- dropout
- GNN
- R
- pandas
Archives
- Today
- Total
끄적거림
[논문 리뷰] Active Learning by Feature Mixing 본문
728x90
반응형
https://arxiv.org/pdf/2203.07034.pdf
https://www.youtube.com/watch?v=T9VKaTlKlMw
cvpr 2022에 나온 논문으로 유튜브 설명을 정리한 내용이다.
Introduction - Active Learning
- 초기 학습된 모델을 통해 labeling을 했을 때, 가장 성능을 빠르게 높일 수 있는 unlabeled data를 sampling하는 것이 중요.
Introduction - uncertainty
- Random: unceratinty에 대한 측정 없이 random하게 sampling 하여 라벨링을 진행 -> 베이스라인으로 쓰임
- Least Confidence: confidence값을 기준으로 낮은 값을 보인다면 uncertainty가 높다고 판단하여 샘플링
- Margin Sampling : max(confidence) - second(confidence)로 uncertainty를 구함
- Entropy Sampling : entropy loss로 uncertainty로 씀.
Related Work
- Active Learning 방법론의 핵심은 라벨링이 필요한 query sample들을 선택하는 scoring 방식.
- 대표적으로 uncertainty 기반의 방법론, representation 기반의 방법론, 둘을 합친 하이브리드 방법론으로 나눌 수 있음.본 논문에서 다루는 모델은 아래 그림과 같음

- uncertainty 기반의 대표적인 방법론 (BALD) : Deep Bayesian Active Learning with Image Data에서 제안한 Bayesian Uncertainty Estimation을 사용한 방법론.
- MC dropout을 사용하여 uncertainty를 측정함.
- 단점은 오랜시간 걸린다는 점.
- representation 기반의 대표적인 방법론 (Core-Set) : Active Learning for Convolutional Neural Networks
- A Core-set Approach 논문에서 uncertainty를 정량화하는 것이 아니라 전체 unlabeled dataset을 커버할 수 있는 core unlabeled dataset을 선별한느 방식.
- 빠른 속도로 학습할 수 있음.
Method

- 모델의 confidence로 uncertainty를 선별하는 것이 아니라, 모델의 representation vector의 정보를 활용하여 training dataset에 포함되지 않은 novel sample을 선택하는 방법론을 제안함.
- novel sample을 어떻게 선택함?
- 라벨링된 데이터와 라벨링되지 않은 데이터간의 representation vector의 convex combination을 통해 mixed representation vector를 생성했을 때, 해당 representation vector에 대한 모델의 loss 변화를 통해 novel sample을 정의함.
- 위 그림에서처럼, unlabeled sample이 들어왔을 때의 모델의 psuedo label과 labeling된 dataset representation vector를 convex combination을 함.
- 이때의 mixed representatioin에 대한 모델의 classification 결과가 변한다면, 라벨링이 필요한 데이터다. 라고 정의함.
- 즉, novel sample은 anchor representation vector와의 차이가 크고, pseudo label에 대한 gradient 값이 큰 sample을 의미함.
- 결과적으로, 라벨링되지 않은 데이터에 약간의 노이즈를 주었을 때, 분류 결과가 달라진다면, 라벨링이 필요한 데이터다. 라고 생각할 수 있다.
- 알고리즘
- 각 학습 단계마다 labeling이 필요한 unlabeled data sample B개를 선택하는 과정
각 class에 속하는 $z^*$에 대한 $\alpha$ - unlabeled sample에 대한 diversity를 높이기 위해 clustering을 진행함.
- 각 학습 단계마다 labeling이 필요한 unlabeled data sample B개를 선택하는 과정

- 위 그림은 본 논문에서 제안한 방법론을 적용했을 때, unlabeled sample에 대한 representation vector를 임베딩 공간에 시각화한 그림으로, 본 논문에서 제안한 ALFA-Mix 방법론이 class boundary에 모여 있는 것을 알 수 있다.
Experiment

- 4개의 데이터셋과 8개의 방법론에 대한 실험을 진행
- 본 방법론이 비교 방법론 대비 몇 % 성능 향상이 있었는지를 나타낸 그림
- 모든 케이스에서 제안한 방법론이 효과가 좋았다.

- 총 30개의 다른 실험환경에서 제안된 모델의 성능을 비교한 것
- 행의 방법론이 열의 방법론보다 성능이 좋았던 횟수의 비율을 나타낸 것
- 마지막 행은 전체 열에 대한 평균값으로, 다른 방법론 대비 성능이 낮았던 경우를 의미하므로, 수치가 작을수록 성능이 좋았다고 볼 수 있다.

- 실제 실험: 3가지 데이터셋에서 실험 했는데, 성능이 가장 우수했음
- 5번의 반복 실험을 했을 때, 성능 편차를 음영으로 나타냄. 제안된 방법론은 음영이 거의 보이지 않으므로 robust할 수 있다고 할 수 있다.
- 초기 학습때, 성능 향상 기울기가 가장 가파르다.
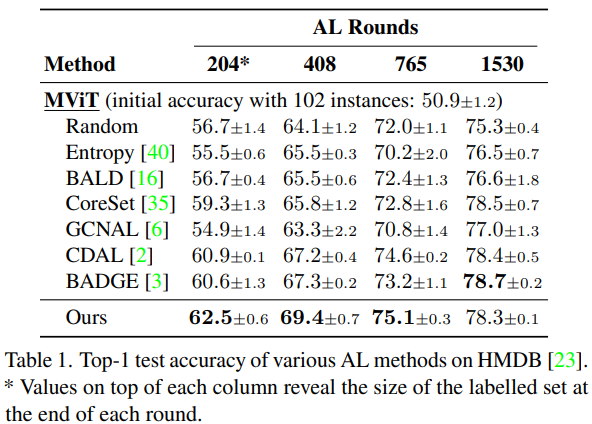
- ViT 모델 기반에서도 성능이 높다.

- 비디오 classification에서도 우월한 성능을 보임. SOTA 성능.
- 최종적으로 labeled data의 갯수가 많아져서 classification 성능이 어느정도 수렴을 했을 때에도, 다른 방법론 대비 높은 성능을 보임.

- diversity에 대한 실험
- clustering으로 sampling을 진행했는데, clustring 뿐 아니라 $Norm,~ Symmetric-KL, ~ Uniform$ 방법론도 함께 비교함.
- Norm: interpolation hyper parameter인 $\alpha$ 값이 가장 작은 sample을 선택하는 방법. $\alpha$에 대해 최적화 과정이 없으면, final prediction이 변경되는 data의 개수가 크게 감소함.
- Symmetric-KL: loss 값의 변화가 가장 컸던 sample을 KL divergence를 이용해 구하는 방법
- Uniform : random하게 sampling하는 방법(베이스라인)

- 시간 효율성이 좋다.
- 가장 간단한 방법인 entropy와 비슷한 수준이다.
- BALD는 러닝타임이 굉장히 길다
classification boundary를 찾아내는 것이 중요하다고 생각했는데, 이를 구현한 방법론인 것 같아 많은 도움이 되었다.
728x90
반응형
'개인 공부 정리 > ML&Statistic' 카테고리의 다른 글
| inductive bias 참고글 (0) | 2021.08.06 |
|---|---|
| Parameterization 개념 (0) | 2021.03.19 |
| 혼동행렬(Confusion Matrix)와 ROC, PR - curve 설명 (0) | 2020.11.19 |
'개인 공부 정리/ML&Statistic' Related Articles
more

Comments