
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- pandas
- pytorch
- R
- 빅데이터
- uncertainty
- 파이썬
- 데이터분석
- 백준
- Crawling
- DATA
- Graph
- AI
- 강화학습
- 크롤링
- 텍스트마이닝
- 리눅스
- VAE
- PYTHON
- 불확실성
- 우분투
- 베이지안
- 텍스트분석
- YarinGal
- bayesian
- GNN
- 코딩테스트
- dropout
- 논문리뷰
- selenium
- 알고리즘
- Today
- Total
끄적거림
[논문 리뷰] Dropout as a Bayesian Approximation 설명 - 4.Related Research (2): Background(Gaussian Process) 본문
[논문 리뷰] Dropout as a Bayesian Approximation 설명 - 4.Related Research (2): Background(Gaussian Process)
Signing 2021. 1. 28. 23:13[논문 리뷰] Dropout as a Bayesian Approximation 설명 - 1.Prologue
[논문 리뷰] Dropout as a Bayesian Approximation 설명 - 2.Abstract
[논문 리뷰] Dropout as a Bayesian Approximation 설명 - 3.Introduce
[논문 리뷰] Dropout as a Bayesian Approximation 설명 - 5.Methodolgy
[논문 리뷰] Dropout as a Bayesian Approximation 설명 - 6.Experiment
[논문 리뷰] Dropout as a Bayesian Approximation 설명 - 7.Conclusion
[논문 실습] Dropout as a Bayesian Approximation 실습 코드 - pytorch ver
Gaussian Process
다음은 가우시안 프로세스이다.
다소 생소할 수 있는 개념이다.
나도 가우시안 프로세스에 대해서는 아직 공부중이긴 하나, 본 논문을 이해하기 위한 최소한의 개념만 짚고 넘어가도록 하겠다.
가우시안 프로세스를 이해하기 위해서는 random process(R.P.)를 먼저 알고 있어야하고, R.P.를 이해하기 위해서는 random variable(R.V.)을 선이해해야한다.
Random Variable(이하 R.V.)
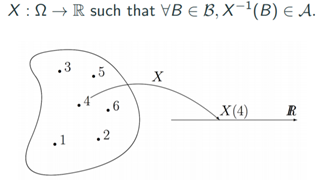
그렇다면 먼저 R.V.부터 알아보도록 하자.
R.V.는 통계를 하는 사람들에겐 매우 익숙한 개념이지만, 정확한 개념은 다음과 같다.
"sample space의 element를 real-line으로 mapping시키는 function"
말이 어렵지 하나씩 까놓고 보면, 일단 sample space라고 하는 것은 함수론에서의 정의역과 같은 의미이다.
내가 낼 수 있는 요소들의 집합인 것이다.
예를 들어 정육면체인 주사위를 보면, 이 주사위의 sample space는 1,2,3,4,5,6 이란 공간이 되는 것이고, 여기서 각 숫자인 1,2,3,4,5,6을 element라고 한다.
real-line은 실수(유리수와 무리수의 합집합)이다.
함수론 관점에서는 치역이라고 보면 된다.
흔히 생각해서 어떤 확률 값이라고 생각해도 된다.
그 다음은 function이라고 했다.
다시 주사위 예로 돌아와서 보면, 1,2,3,4,5,6의 element 중에서 1이 나올 확률은 1/6이다.
이 말을 다시 쓰면, {1,2,3,4,5,6}의 공간에서 1이란 요소를 1/6이라는 실수 값을 갖는 확률값으로 mapping시키는 function이 R.V.이 된다.
여기서 다소 수학적이지 못한(?) 개념이 나온다.
의미상 function은 맞다.
왜냐하면 어떤 정의역 값을 받아서 치역 값으로 내뱉으니까...
근데 뭔가 수학적 개념보다는 추상적 개념이다. 우리의 눈에 보이지 않는 함수를 다룬다고할까나,,,(이건 내생각)
Random Process(이하 R.P.)

R.P.는 R.V.의 확장판이다.
R.V.은 하나의 실수값만 다루는 scala 값을 가졌다면, R.P.는 vector값을 갖는다.
그것도 무한차원의 벡터값을 갖는다.
여기서 무한차원의 벡터는 함수(function)랑 같다.
응? 이게 머선말이고?
천천히 이해해보도록 하자!
일단, 함수는 실수들의 집합이다.
그리고 무한차원의 벡터는 여러 실수들을 각 차원에 둔 벡터이므로 무한차원의 벡터 역시 실수들의 집합이라 할 수 있다.
다소 억지스러운 면이 있지만, 그렇다고 한다.
그럼 다시 돌아와서, R.P.는 무한차원의 벡터 값을 갖는다고 했으니 이는 곧 함수를 갖는다는 말과 같다.
그렇다. R.P.는 sample space의 element를 각각의 function으로 mapping이 된다.
하나의 element를 끄집어 내면 함수가 튀어나오는 것이다.
그림을 보면 이해가 좀 될 것이다.
보통 R,P.의 element는 시간, 공간따위를 자주 설정한다.
그러면 그림에서처럼 시간에 따라 함수가 변하는 꼴이 된다.(인정?)
와닿지 않는다,,, 먼말이야,, 무한차원의 벡터부터 시간에 따라 변하는 함수라니,,,
이 R.P.의 가장 대표적인 예로는 브라운 운동이 있다.
브라운 운동이란?
참고: ko.wikipedia.org/wiki/%EB%B8%8C%EB%9D%BC%EC%9A%B4_%EC%9A%B4%EB%8F%99

이것도 사실 와닿지 않는다.
그런가보다,, 싶다.
그래서 이미지상 이해하기 쉬운 예를 가져왔다.
뉴스나 이슈 프로그램 같은 곳에서 음성변조하는 영상이 나올때 배경으로 어떤 주파수가 막 떨리는 영상을 본 경험이 한 번쯤은 있을 것이다.

이 주파수를 일종의 함수라고 생각하면, 이 함수는 매 시간, 즉, 말하는 사람이 계속해서 말을 할 때마다 그 주파수가 바뀌면서 함수의 모양도 바뀐다.
실제로 이런 예시가 R.P.를 따르는지는 아직 잘 모르지만 그냥 이런 느낌으로 이해해주면 될 것 같다.
Gaussian Process(이하 G.P.)

G.P.는 R.P의 일종이며, 정의에 따르면, Gaussian 분포를 jointly하게 따르는 R.V.들의 집합이다.
한마디로, 정규 분포를 따르는 확률변수들이 jointly하게 엮여있으면 되는 것이다.
여기서 jointly하다는 것은 multi-variative normal distribution을 생각해도 좋다.

표기는 위와 같이 쓴다.
정규분포를 정의하는 parameter는 mean과 variance가 있었다.
G.P.를 정의하기 위해서는 mean function과 covariance function이 있어야 한다.
G.P. 자체가 이미 함수를 다루고 있기 때문에 G.P.를 정의하기 위해서는 mean function과 covariance function을 알아야하는 것이다.

가우시안 분포에서도 가장 일반적이고 보편적인 분포는 평균이 0인 표준정규분포였다.
G.P.에서도 동일하다.
zero-mean을 가정하는 G.P.를 다룰 것이다.
zero-mean G.P.는 결국 covariance function에 의해서 모든 것이 결정된다.
여기서 covariance function은 표기를 K라고 표기했다.
이유는 G.P.의 covariance function을 kernel function으로도 정의하기 때문이다.
kernel function,,, 분명 익숙하다.
아마 머신러닝을 배울 때 SVM 파트에서 많이 언급되었을 것이다.
SVM에서 kernel을 보통 고차원으로 보내는 function으로 이해하고 넘어가는 사람들이 대부분일 것잇다.
사실 kernel은 꽤 어려운 개념이고 복잡하다.
완전히 이해하길 원한다면 첫번째 포스팅에도 링크 걸어놓았던 최성준 박사님의 edwith 강의를 참고하길 바란다.
www.edwith.org/bayesiandeeplearning
Bayesian Deep Learning 강좌소개 : edwith
- 최성준
www.edwith.org
나는 간단하게 다루고 넘어가도록 하겠다.
사실 이 개념도 edwith의 문인철 교수님의 강의에 포함된 내용이니 같이 확인해보면 좋을 듯하다.
www.edwith.org/aiml-adv/lecture/21289/
[LECTURE] Gaussian Process: Introduction (1) : edwith
- 송경우
www.edwith.org
Kernel
먼저 우리가 흔히 알고있는 kernel에서 출발해보자.
이제부터 나오는 사진들은 내가 문인철 교수님의 강의를 듣고 직접 필기한 그림이다.

흔히 알고 있는 kernel은 저차원에서 고차원으로 보내는 함수라고 알고 있고, 위의 그림은 이를 그림으로 나타낸 것이다.
여기서 kernel function을 phi(피) 라고 부르는데, phi가 위와같이 구성이 되어있다고 가정하면, phi는 2차원이었던 input들에 대해 3차원의 공간인 고차원으로 보내버리는 함수인 것이다.

여기에 단순 선형회귀식을 대입하여 phi를 적용시켜보면 위와 같은 방식대로 식을 정리할 수 있다.
여기서 w는 각 항의 parameter로 볼 수 있다.
우리가 알고있는 것은 w를 어떤 고정된 모수라고 생각하고 이를 구하려는 작업을 진행하는 것이었다.
하지만, 이제 w를 고정된 값이 아닌 어떤 분포라고 생각해보자.
일정 확률에 의해서 매번 다른 값이 튀어 나오는 분포를 갖는다 가정해보자.
분포가 되기 위해서는 1) shape 2) parameter가 필요하다.
이 세상에는 수많은 분포가 존재하기 때문에 가장 흔하고 자연에서 많이 발생하는 정규분포를 생각해보자.

그러면 w에 대한 확률분포는 위의 그림과 같이 쓸 수 있다. --> p(w) = N( w|0, alpha^(-1)*I )
zero-mean을 가정하였고, 여기서 alpha는 분산의 값을 의미한다.(noise, 퍼짐의 정도라고 볼 수 있다.)
w가 벡터이기 때문에 단일값의 분산이 아닌 메트릭스를 값는다.
그렇기 때문에 I matrix(=identical matrix)를 사용한다.
이것은 공분산이 없고, 대각원소만 존재한다는 뜻이므로 다룬 요소들에 의존적이지 않음을 의미한다.
이제 w에 대한 분포를 정의했으니, Y의 평균과 분산을 그림에서처럼 구할 수 있고, 그렇기 때문에 Y의 분포도 정의할 수 있다.
여기서 우리가 주목해야할 것은 (공)분산행렬이 kernel function으로 나온다는 점이다.
이것이 의미하는바는 다음과 같다.
공분산함수(행렬)은 kernel 함수와 같다!
놀랍게도 공분산함수가 kernel function과 같다는 말이다.
사실 이렇게 간단한 증명이 아니다.
(자세한건 최성준 박사님이나 문인철 교수님의 edwith 강의에서,,, 기회가 되면 다뤄보도록 하겠다.)
kernel function을 좀 더 면밀히 살펴보면, 사실 kernel은 어떤 두 input에 대해서 함수를 적용한 뒤 나오는 함수값의 닮음의 정도, 비슷한 정도를 나타내고 있다.
그렇기 때문에, 두 input에 대한 output의 비교값 = 두 input의 correlation = auto-correlation으로도 생각할 수 있다.
이 kernel function의 값이 만약 가까운 두 input에 대해서 급격히 변한다면, 이는 그만큼 함수가 굴곡이 심하다는 이야기 혹은 큰 변화량을 갖는 것으로 이해할 수 있다.
Gaussian Process Regression(G.P.R.)
이제 kernel이 왜 G.P.의 공분산자리에 위치해 있는지 이해했다.
그럼 한발만 더 나아가서 간단히 G.P.R.도 알아보겠다.

그림의 왼쪽은 2차원 공간에 데이터가 산재되어 있는 것을 볼 수 있고, 오른쪽 그림은 이를 G.P.로 fitting한 모습이다.
파란 실선은 G.P.의 mean function을 의미하고, 회색으로 음영처리 된 부분은 G.P.의 cov function(=kernel function)을 나타낸 것이다.
이렇듯 우리는 G.P.를 통해서 data를 fitting 시켜서 regression을 수행할 수 있다.(G.P.R.)
G.P.R.의 장점은 데이터 전체를 한 번에 모델링 할 수 있음과 covariance function으로 불확실성을 측정할 수 있다는 것이다.
하지만, regression task에서는 기존의 data를 fitting하여 모델링 하는 것도 중요하지만, 새로운 input이 들어올 때 잘 예측하는 것도 중요하다.
G.P.R.에서는 새로운 input에 대해서 어떻게 처리할까?

x*가 new input이라고 보면 된다.
일단 그림에서 x*를 갖는 부분이 없다고 생각해보자.
기존의 G.P.R. 모델일 것이다.
여기에 x*가 추가된 그림으로 인식해보자.
G.P.의 정의에서처럼 G.P.는 R.V.의 collection이므로 gaussian을 따르는 새로운 input이 들어와도 여전히 G.P.모델이다.
이런식으로 G.P.에서 regression이 이뤄진다.



