
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- 텍스트분석
- PYTHON
- 베이지안
- 백준
- 텍스트마이닝
- 빅데이터
- 알고리즘
- pandas
- bayesian
- 우분투
- uncertainty
- 논문리뷰
- R
- 파이썬
- 데이터분석
- 강화학습
- VAE
- selenium
- dropout
- Graph
- GNN
- pytorch
- 리눅스
- YarinGal
- DATA
- 크롤링
- 코딩테스트
- Crawling
- AI
- 불확실성
- Today
- Total
끄적거림
[논문 리뷰] Learning Transferable Graph Exploration - 4.Experiments - (2) Generating Inputs for Testing Domain Specific Programs 본문
[논문 리뷰] Learning Transferable Graph Exploration - 4.Experiments - (2) Generating Inputs for Testing Domain Specific Programs
Signing 2021. 3. 21. 00:24[논문 리뷰] Learning Transferable Graph Exploration - 0.Abstract
[논문 리뷰] Learning Transferable Graph Exploration - 1.Introduction
[논문 리뷰] Learning Transferable Graph Exploration - 2.Problem Formulation
[논문 리뷰] Learning Transferable Graph Exploration - 3.Model
[논문 리뷰] Learning Transferable Graph Exploration - 4.Experiments - (1)Synthetic 2D Maze Exploration
[논문 리뷰] Learning Transferable Graph Exploration - 4.Experiments - (3)App Testing
[논문 리뷰] Learning Transferable Graph Exploration - 5.Related work & 6.Conclusion
4.2 Generating Inputs for Testing Domain Specific Programs
이번 절에서는, 프로그램 test에서 transferable 탐색의 효율성에 대한 연구가 이루어졌다.(coverage guided fuzzing이라 불리기도 함.)
이번 설정에서는, 본 논문에서 지안하는 모델은 가능한 많은 코드의 분기를 커버하는 것을 목표로 test중인 프로그램에 대한 input(test case)를 어떻게 생성해낼지에 대하여 소개한다.
본 논문에서 소개하는 알고리즘을 두 개의 언어(RobustFill, Karel)로 작성된 도메인 특화 프로그램(Domain Specific Languages, DSLs)에 대한 각각 두 개의 데이터셋으로 test를 진행했다.
RobustFill DSL은 concatenation, substring 등과 같은 문자 조작 언어인 정규표현식이다.
Karel은 DSL은 교육용 언어인데 grid world를 프로그래머틱하게 탐색하는 agent를 정의하는데 주로 사용한다.
이 언어는 RobustFill보다 훨씬 더 복잡하다. 왜냐하면 if/then/else 블록과 같은 조건부 statement와 for/while과 같은loop를 포함하기 때문이다.

<Table 1>은 두 데이터셋에 대한 통계치를 요약한다.
Karel의 경우, 공인된 train/validation/test set으로 분리된 데이터셋을 사용하였지만,
RobustFill의 경우, 학습 데이터는 RobustFill: Neural Program Learning under Noisy I/O (arxiv.org)에서 소개된 프로그램 신시사이저를 사용하여 생성되었다.
RobustFill의 경우 agent action들이 input string을 생성하기 위한 일련의 문자열이고,
반면에 Karel의 경우 action들이 (<그림 3>에서 예제 프로그램과 생성된 두 개의 map layout 처럼) 2D array의 문자열이다. RNN으로 encoding되고 생성되었다.
RL을 사용한 모델의 나머지 부분과 jointly하게 엮이는 큰 action spaces을 RNN으로 학습하는 것은 매우 어려운 작업이다.
Main Results
본 논문에서는 두 개의 baseline을 비교했다.
- uniform random policy
- 전문가가 만든 specialized heuristic algorithm
논문에서 최적화하기 위한 object function은 (Karel의 경우) 고유한 code 분기 혹은 (RobustFill의 경우) 생성된 input에서 프로그램을 실행할 때 trigger되는 정규표현식이며, 이것은 생성된 input에 대한 퀄리티를 나타내는 좋은 지표이다.
현재의 AFL같은 fuzzing tool 또한 coverage-guid이다.
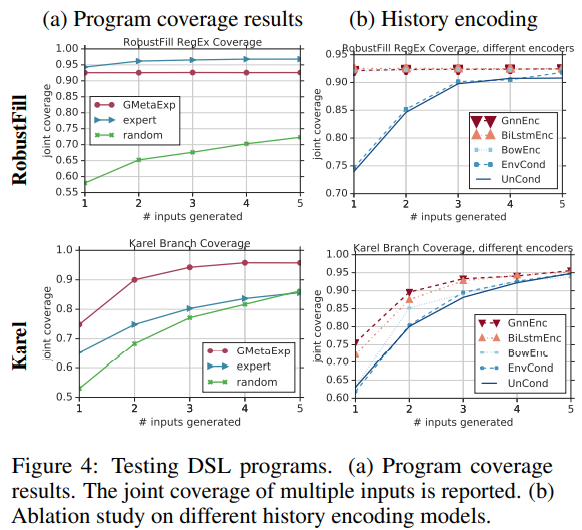
<그림 4(a)>는 각기 다른 방법의 coverage performance를 나타낸 것이다.
RobustFill을 보면, 논문에서 제시한 방법은 전문가 level의 수행능력까지 도달하였고, 둘 다 90%을 웃도는 coverage에 도달하였다.
dataset이 사람이 만든 input에 대부분의 coverage를 얻은 샘플로 생성되었기 때문에, 평가 자체가 전문가쪽으로 편향될 수 밖에 없다.
그럼에도 불구하고, GMetaExp은 software testing에서 범용적으로 사용되는 random fuzzing 접근방법 보다 더 좋은 성능을 내었다.
Karel 프로그램의 경우, GMetaExp는 전문가보다 확실히 더 좋은 결과를 냈다. 전문가가 복잡한 조건문 및 루프 문을 가진 프로그램에 대한 입력을 생성하기 위해 heuristic 알고리즘을 개발하는 것이 훨씬 더 어렵기 때문이다
Comparing to fuzzers
fuzzing 접근방법을 비교하기 위해, 본 논문에서는 AFL과 Neuzz를 적용하였다.
FAL과 Neuzz가 afl-gcc에 필요하기 때문에 모든 Karel 프로그램을 C언어로 변환하였다.
AFL을 사용한 test case를 생성하는데 있어서 가이드라인을 제공하기 위해 vocabulary와 fuzzing 전략을 제한하였다.
각 프로그램당 10분정도를 AFL을 실행했고, unique한 execution trace가 있는 test case를 사용하여 coverage를 살펴보았다.
$n$개의 distinct한 execution trace인 AFL 혹은 Neuzz를 얻는 것은 $N >> n$ test case가 더 나았다.
Neuzz도 비슷하게 설정되지만, AFL의 출력을 초기값으로 설정했다.

<Table 3>를 보면, 논문에서 제안하는 접근 방식은 1번의 test case에서 0.75 정도의 coverage와 5번의 test case에서는 0.95정도의 coverage를 보였다. 이것은 AFL과 Neuzz보다 훨씬 더 효율적이다.
그에 따라, 하나의 test case만 허용될 때, 같은 random 환경(random seed가 동일한 느낌)에서 AFL과 Neuzz는 각각 0.53과 0.55 정도의 coverage를 얻었다.
또한, 본 논문에서는 오랫동안 범용적으로 사용된 Neuzz보다 다음 새로운 프로그램의 input을 바로 예측할 수 있었다.
하지만 본 논문에서 사용한 접근 방식은 fuzzing task에서 일반적인 문제에서는 어려움이 있다.
예를 들어 Neuzz의 benchmark는 몇 개의 프로그램으로 구성되며 small dataset size로 인해 프로그램 전반의 일반화에 집중한 학습 기반 접근 방식을 사용하기는 어렵다.
반대로, 소개한 접근방식은 큰 규모의 프로그램에서는 적용하기가 어려운 부분이 있다.
SMT solver는 복잡한 논리로 작은 function을 분석하는데 초점을 맞추고 있기 때문에 소개된 접근방식과 비슷하다
Comparing to SMT solver
Karel에서 수기적으로 좋은 heuristic을 디자인하기는 어렵기 때문에, 프로그램 coverage의 최대화할 수 있는 input을 찾기 위해 사용하는 Z3 SMT solver를 symbolic execution을 베이스라인으로 적용했다.
symbolic execution 베이스라인은 전체 시간이 4시간으로 주어진 시간적 예산 안에서 467개의 test 프로그램 중 412개의 최적해를 찾아내었다.
하나의 input을 사용하여 해결한 412개의 case에 대한 평균 점수는 0.837이고, 이것은 하나의 input 적용 범위에 대한 대략적인 "upper bound"이라 볼 수 있다.(solving time을 추적 가능하도록 최대 경로 수를 100으로 제한하고 loop가 도는 동안 최대 확장 수를 3으로 제한하므로 최적이라는 것을 보장하진 않는다.)
그와 반대로, GMetaExp는 하나의 input이 있을 때 평균 점수가 0.76이었고, 모든 test 프로그램을 돌릴 때 몇 초 밖에 걸리지 않았다.
symbolic execution 접근방식은 평균적으로 더 높은 coverage를 갖는 반면에, 느리고 가끔 loop 구조에 깊게 빠지는 solve case는 실패로 돌아간다.(예를 들어, while loop나 nested repeat)
SMT solver가 실패한 어려운 case(상위 100개의 모든 잠재 path를 확인한 후에도 solution을 찾지 못한 case)에서, 본 논문에서 제안한 접근 방법은 0.689 coverage를 얻었다.
이것은 GMetaExp가 computation cost와 accuracy 사이에서 적절한 좋은 벨런스를 갖는 것을 의미한다.


<그림 3>과 <그림 6>는 두 test 프로그램 예제에 대해 GMetaExp를 사용하여 생성한 test input을 시각화 한 것이다.
cover된 정규표현식 혹은 분기점은 주확색으로 강조해 놓은 것이다.
random하게 생성된 input은 프로그램의 적은 부분만 cover할 수 있었던 것을 관찰할 수 있었다.
반면에, 논문에서 제안한 방법으로 생성한 input은 더 많은 분기점에서 trigger할 수 있었다.
게다가 프로그램 또한 실행 뒤 제안된 방법으로 생성한 input으로 재밌는 조작이 수행되었다.
Effectiveness of program-aware inputs
random하게 생성된 프로그램 input으로 비교할 때, 논문에서 제안한 학습된 모델은 coverage 부분에서 훨씬 더 좋은 성능을 보였다.
그러나 random generation은 속도와 효율성은 서로 trade-off 관계에 있다.(random input을 생성하는 것이 제일 빠르다)

그러므로 더 많은 sample budget으로 random generation을 평가했고, 10개의 input으로 random generation은 73%의joint coverage에 도달(즉, 여러개의 생성된 test input을 사용한 graph node/프로그램 분기의 coverage의 조합)할 수 있지만, 100개의 input으로도 coverage는 85%에 불과했다.(Appendix 그림 7)
이것은 한 개의 input으로 93%의 coverage를 얻을 수 있기 때문에 학습된 모델의 유용성과 생성된 program-aware input을 보여준다.
Comparison of different conditioning models
다른 두 탐색 history encoder에 대한 효율성도 본 연구에서 진행되었다.
여기서 고려하는 encoder는
- `UnCond`
policy network가 프로그램 혹은 task에 대해 아무것도 모르는 상태이며, 'good' test case를 일반화시키는 것을 목적으로한다.
과거의 test case들을 $F(h_t)$의 autoregressive parameterization를 통하여 제안된 것으로 여겨진다. - `EnvCond`
policy network가 프로그램을 모르지만 새로운 actin이 실행될 때 이전의 action이 반영된 external reward를 얻는다.
이것은 agent가 environment와의 historical 상호작용에 기반한 adaptive policy를 학습하는 meta RL과 유사하다. - `program-aware model`
프로그램의 encoding에 기반한 policy network를 갖는다.
본 논문에서는 `BowEnc, back of word encoder`, `BiLstmEnc, bidirectional LSTM encoder`, `GnnEnc, graph neural netwrok encoder`를 사용했다.

<그림 4(b)>는 다른 encoder에 대한 ablation 결과를 보여준다.
RobustFill의 경우, DSL이 상대적으로 간단해서, 모델의 성능은 프로그램을 따라가는 경향이 있다.
Karel의 경우, `GnnEnc`가 최고 성능을 냈고, 특히 input의 갯수가 적을 때와 같은 exploration budget일때 더 그랬다.
한가지 흥미로웠던 것은 프로그램에 의존하지 않았던 `Uncond`도 좋은 성능을 냈다는 것이다.
이것은 이런 dataset에서의 RL을 통한 일반적으로 좋은 탐색 전략을 찾을 수 있음을 시사한다.
이것은 또한 empty strings, null pointers 등과 같은 corner cases test를 위한 공통 전략이 있는 osftware testing practice와도 일치한다.