
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- 파이썬
- 강화학습
- 빅데이터
- pandas
- 베이지안
- 논문리뷰
- pytorch
- 텍스트분석
- 우분투
- Crawling
- AI
- Graph
- PYTHON
- VAE
- DATA
- 불확실성
- 백준
- R
- bayesian
- 텍스트마이닝
- selenium
- dropout
- uncertainty
- GNN
- YarinGal
- 코딩테스트
- 데이터분석
- 크롤링
- 알고리즘
- 리눅스
- Today
- Total
끄적거림
[논문 리뷰] Learning Transferable Graph Exploration - 4.Experiments - (3)App Testing 본문
[논문 리뷰] Learning Transferable Graph Exploration - 4.Experiments - (3)App Testing
Signing 2021. 3. 22. 19:22[논문 리뷰] Learning Transferable Graph Exploration - 0.Abstract
[논문 리뷰] Learning Transferable Graph Exploration - 1.Introduction
[논문 리뷰] Learning Transferable Graph Exploration - 2.Problem Formulation
[논문 리뷰] Learning Transferable Graph Exploration - 3.Model
[논문 리뷰] Learning Transferable Graph Exploration - 4.Experiments - (1)Synthetic 2D Maze Exploration
[논문 리뷰] Learning Transferable Graph Exploration - 4.Experiments - (3)App Testing
[논문 리뷰] Learning Transferable Graph Exploration - 5.Related work & 6.Conclusion
4.3 App Testing
이번 절에서는 탐색과 mobile app의 test에 대한 연구이다.
모바일 어플은 굉장히 크고 소스코드는 커머셜 어플의 경우 coverage 측정과 모델링에 대해 가능하지 않다. 왜냐하면, 코드 분기 level이 매우 expensive하고 종종 불가능하기 때문이다.
그에 대한 대안은 사용자 상호작용이 가능한 unique한 screen의 수를 측정하는 것이다.
여기 각 screen은 사용자가 상호 작용할 수 있는 다양한 기능과 UI적 요소를 포함하고 있으며, 화면 간의 다양한 전환을 탐색하기 위해 서로 다른 상호 작용 테스트를 하는 것이 버그와 충돌을 발견하는 좋은 방법이다.
본 연구에서는 각각의 어플에 대해 screen을 graph로 바꾼 것을 상호작용 budget $T=15$이었고, unknown environment를 탐색하는 설정이었다.
각 step에서 agent는 `search query`, `click`, `scroll` 등과 같은 사용자 상호작용 action의 유한한 집합을 고를 수 있었다.
node의 feature는 화면의 시각적인 모양, 레이아웃 또는 UI적 요소의 encoding 혹은 continuous testing 시나리오에서의 과거 test log의 encoding에서 비롯될 수 있다.
더 자세한 setup과 결과는 appendix B.7에 수록되어 있다.
Dataset
Android 앱스토어의 여러 어플들을 스크랩했고 적어도 20개의 distinct한 screen을 가지는 1000개의 어플을 수집하였다.
그 중의 5개를 held-out evaluation으로 사용했다.
학습하는 동안 안드로이드 어플 시뮬레이터와 expensive한 상호작용을 피하기 위해서, 사용자 입력을 사용하여 오프라인에서 이런 어플을 테스트하고 각 앱에 대한 화면 전환 그래프를 추출했다.
그런 다음 기록된 graph를 기반으로 화면 간 전환하는 경량 오프라인 앱 시뮬레이터를 구축했다.
오프라인 시뮬레이터와 상호작용하는 것은 저렴했다.
실제 앱 데이터셋 외에도, 접근 방식의 수용성을 추가로 테스트하기 위해 synthetic 어플 데이터셋도 만들었다.
Erdos-Rényi(이하 ER)에서 random하게 샘플링한 graph는 15~20개의 노드와 edge의 확률이 0.1이고 synthetic 어플에 대해 화면 전환 graph로써 이 ER 그래프를 사용하였다.(참고: en.wikipedia.org/wiki/Erd%C5%91s%E2%80%93R%C3%A9nyi_model)
훈련을 위해 랜덤 그래프를 생성하고, 일반화 성능을 테스트하기 위해 100개의 held-out graph를 사용한다.
Baselines
4.1절에서 정의된 RandDFS 베이스라인 외에도, 테이블 형태의 Q-learning 베이스라인도 평가했다.
이 Q-learning 베이스라인은 Node의 ID를 state로 사용하였고 탐색 history를 모델링하지 않았다.
상태 표현에 현재 노드 ID만 포함되어 있는 경우 MDP는 정지 상태가 아니기 때문에 이러한 제한으로 Q-러닝은 최적의 전략을 학습할 수 없게 된다.
또한, 이 접근 방식은 표 형식이기 때문에, 새로운 graph로 일반화되지 않으며 일반화 설정에서 사용될 수 없다.
본 논문에서는 고정된 iteration 횟수에서 각 graph에 대해 개별적으로 이 베이스라인을 학습하고 해당 graph에 도달할 수 있는 최고의 성능을 말하고 있다.
Evaluation setup
연구에서 제안한 알고리즘을 두 개의 시나리오(fine-tuning과 generalization)로 평가했다.fine-tuning의 경우, agent는 필요한 많은 에피소드에서 앱 시뮬레이터와의 상호작용을 한다. 그리고 본 논문에서는 어플에서 fine-tuning해온 알고리즘의 성능을 나타낸다.그 대신에, 이것은 많은 RL task에서 '여러 앱을 학습하고 평가하는 설정'이라 생각될 수 있다.generalization 시나리오의 경우, agent는 학습한느 동안에 보지 못했던 어플에서 single 에피소드 내에서 가능한 많은 보상을 받으려 한다.첫번째 시나리오에서 tabular Q-learning 접근 방식 random 탐색보다 더 강력하다는 것을 비교했었다.두번째 시나리오에서는, tabular policy가 generalizable하지 않기 때문에, random 탐색을 베이스라인으로 사용하였다.
Result
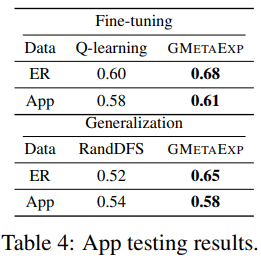
<table 4>는 각각 다른 데이터셋에 대한 각각 다른 접근방법에 대한 결과를 나타낸 것이다.
표에서 보이듯, 논문에서 제안한 graph 구조와 탐색 history와 learning setup에 대한 모델링을 보면, GMetaExp 알고리즘이 fine-tuening과 generalization 실험에서 Q-learning과 random 탐색 베이스라인보다 더 좋은 성능을 낸 것을 볼 수 있다.
게다가, 논문에서 제안한 zero-shot generalization 성능은 tabular Q-laerning의 fine-tuned 성능보다 훨씬 더 좋은 것을 알 수 있다.
이것으로 탐색을 위해서 사용자 입력을 제안할 때, 구조적 history의 embeding의 중요성을 보여주고 있다.

<그림 5>는 synthetic app graph에 대한 100개의 test graph에서 learning from scratch와 fine-tuning을 위한 모델의 학습 곡선을 보여주고 있다.
fine-tuning의 경우, 학습된 모델을 초기화 했고, 각각 개별적인 graph에 대해 강화학습을 수행했다.
learning from scratch의 경우, 각각의 개별적인 graph를 분리하여 학습시켰다.
그래서 본 논문에서는 다음의 두 가지를 관찰하였다.
- generalization performane는 fine tuned model과 비슷한 성능을 낼만큼 이번 케이스에서는 꽤나 효과적이었다.
- learning from the pretrained model은 효율적이다는 것이다. learning from stratch보다 coverage가 약간 더 좋게 그리고 더 빠르게 모델을 수렴할 수 있기 때문이다.


