
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- VAE
- 베이지안
- YarinGal
- 코딩테스트
- pandas
- 데이터분석
- 텍스트분석
- 강화학습
- bayesian
- R
- 빅데이터
- 리눅스
- pytorch
- 백준
- 논문리뷰
- dropout
- selenium
- 크롤링
- uncertainty
- 불확실성
- AI
- 파이썬
- Crawling
- DATA
- GNN
- 우분투
- 텍스트마이닝
- Graph
- 알고리즘
- PYTHON
- Today
- Total
목록전체 글 (154)
끄적거림
 [논문 리뷰] What uncertainties do we need in Bayesian deep learning for computer vision? - 2.Related Work(2)
[논문 리뷰] What uncertainties do we need in Bayesian deep learning for computer vision? - 2.Related Work(2)
[논문 리뷰] What uncertainties do we need in Bayesian deep learning for computer vision? - 1.Introduction [논문 리뷰] What uncertainties do we need in Bayesian deep learning for computer vision? - 2.Related Work(1) 2. Related Work 2.2 Heteroscedastic Aleatoric Uncertainty 본 논문에서는 Homoscedastic을 따로 다루지는 않는다. 그 이유는 Heteroscedastic이 이분산성의 성질을 가지고 있고, Homoscedasticd은 등분산적 성질을 가지고 있기 때문에, Heteroscedastic이 Ho..
 [논문 리뷰] What uncertainties do we need in Bayesian deep learning for computer vision? - 2.Related Work(1)
[논문 리뷰] What uncertainties do we need in Bayesian deep learning for computer vision? - 2.Related Work(1)
이전 글: 2020/11/10 - [논문 리뷰] What uncertainties do we need in Bayesian deep learning for computer vision? - 1.Introduction 2. Related Work 본 논문에서 말하는 불확실성은 결국 분산으로 생각할 수 있다. 우리가 어떤 분포에서 분산을 알 수 있다면, 어느정도의 확률로 예측범위안에 들어올 것이다 를 알 수 있다. 이는 곧 신뢰구간과 비슷한 의미라고 생각하면 되겠다. 논문에서는 uncertainty를 sigma, variance 등과 같은 분산 혹은 어떤 분포로 혼용하여 사용하기도 한다. 기존의 Bayesian Deep Learning(이하 BDL)에서는 epistemic과 aleatoric 둘 중 하나만 ..
 [논문 리뷰] What uncertainties do we need in Bayesian deep learning for computer vision? - 1.Introduction
[논문 리뷰] What uncertainties do we need in Bayesian deep learning for computer vision? - 1.Introduction
베이지안 관련으로 많이 알려진 옥스포드 대학의 yarin Gal 교수가 2017년 Kendall과 함께 발표한 논문이다. 1200회가 넘는 인용이 이루어진 것만 봐도 얼마나 유명한 논문인지를 알 수 있다. 다른 논문들도 읽어보고 포스팅할 계획이다.(시간이 얼마나 걸릴지는 미지수,,) 본 논문을 100% 다 이해하기 위해서는 Random Process, Variational Inference 등과 같은 이론을 알고 있어야하지만, 일단은 공부하는 입장에서 이 논문을 리뷰해보고자 한다. 많이 부족하니 참고용으로 봐주시면 감사하겠습니다. 논문: papers.nips.cc/paper/2017/file/2650d6089a6d640c5e85b2b88265dc2b-Paper.pdf 1. Inroduction 이 단락에..
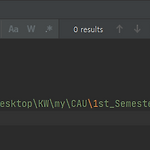 [Tips] pyCharm editor 창에서 원하는 문자 바꾸기
[Tips] pyCharm editor 창에서 원하는 문자 바꾸기
R에서는 쉽게 (ctrl) + (F) 로 원하는 문자를 찾아서 바꿀 수 있었는데 pycharm은 그 기능을 몰랐어서 살짝 헤맸었다. 예를 들어 폴더 주소를 복사해서 붙여넣었을 때, 역슬래쉬가 찍히는 것을 볼 수 있다. 이 역슬래쉬를 제거하고 그냥 슬래쉬로 바꿔주기 위해 아래와 같이 해보았다. 방법 1: (ctrl) + (F) 후 수기 입력 방법 2: (ctrl) + (Alt) + (shift) + (J) 1. 주소 복붙 그냥 폴더에서 주소를 복사해서 넣으면 역슬래쉬 발생 2. (ctrl) + (F) --> 원하는 문자 검색 나같은 경우 \ 문자를 검색했다. 3. 문자 선택 1번을 선택할 경우 하나씩 문자들을 선택하는 것이고, 2번은 전체 다 선택하는 것이다. 나는 2번을 클릭해보겠다. 클릭하면 검색창이 ..
 [데이터셋] PHD08 한글 손글씨 이미지 데이터
[데이터셋] PHD08 한글 손글씨 이미지 데이터
딥러닝, 특히 CNN에서 가장 먼저 접하는 데이터셋이 바로 MNIST일거라 생각된다. MNIST는 0~9까지의 숫자에 대한 손글씨 이미지 데이터이다. 해외에서 공인된 데이터인만큼 데이터를 얻기도 매우 수월하다.(API등과 같은 방법으로) 반면에, 한글에 대한 손글씨 이미지는 찾기 힘들다. 관련해서 구글링하던 중에 한글 손글씨 이미지 데이터를 발견하여 공유하고자 한다. PHD08 www.dropbox.com/s/69cwkkqt4m1xl55/phd08.alz?dl=0 phd08.alz Dropbox를 통해 공유함 www.dropbox.com 2008년에 한글 손글씨 이미지 데이터 구축사업이 전북대에서 진행되었다고 한다. 덕분에 방대한양의 한글데이터를 얻을 수 있었다. 다만 한글의 낱글자에 대한 모든 데이터가..
데이터를 만지다보면 여러 array형 데이터(list/Series in python, vector in R)를 합쳐서 새로운 dataframe 형태로 만들 경우가 생긴다. 보통의 경우 길이가 같은 array들을 이어 붙여야 우리가 원하는 딱 맞는 이쁜 데이터프레임 객체가 생성된다. 하지만 항상 그럴 경우만 생기지는 않으니, 길이가 서로 다른 1차원 자료형을 붙여 dataframe형태로 만들때를 생각해보자! 너무도 당연한 이야기이지만 서로 다른 길이의 1차원 자료형을 붙이면 제일 긴 길이의 데이터를 가지고 데이터프레임 객체가 생성될 것이고, 빈 공간은 NA로써 혹은 Nan 혹은 Null값으로 채워지길 바란다. 우선 R이 편하니 R부터 해보자. 1. R - cbind 다음과 같은 길이가 다른 객체들이 있다. a