
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- Graph
- 텍스트분석
- VAE
- GNN
- 리눅스
- 파이썬
- 빅데이터
- 텍스트마이닝
- 베이지안
- bayesian
- 데이터분석
- 논문리뷰
- PYTHON
- dropout
- 알고리즘
- 백준
- 우분투
- DATA
- YarinGal
- pandas
- selenium
- 코딩테스트
- R
- 크롤링
- pytorch
- uncertainty
- Crawling
- 강화학습
- 불확실성
- AI
- Today
- Total
끄적거림
[논문 리뷰] What uncertainties do we need in Bayesian deep learning for computer vision? - 4. Experiments 본문
[논문 리뷰] What uncertainties do we need in Bayesian deep learning for computer vision? - 4. Experiments
Signing 2020. 11. 16. 17:28
4. Experiments
이 전의 내용들을 바탕으로 몇 가지 실험을 통해 본 논문이 얼마나 실효성을 띄는지를 검증하는 섹션이다.
실험은 다음 두 가지로 task로 진행되었다.
- pixel-wise depth regression
- semantic segmentation
쉽게 생각하면, regression task와 classification task로 진행되었다고 보면 된다.
이 때 사용된 데이터 셋은 CamVid, Make3D, NYUv2 Depth이고, 논문 제출 당시 SOTA급이었다는 설명이 나와있다.
또한, 가장 베이스 아키텍쳐로는 DenseNet 아키텍쳐를 사용했다고 한다.
이전 섹션에서도 소개되었듯이, epistemic uncertainty는 Monte Carlo dropout을 사용하여 구했고, aleatoric uncertainty는 MAP inference를 사용하여 모델링을 진행했다고 한다.
추가로 regression task에서의 loss function에서 L1이 L2가 더 실험적으로 우수함을 밝히고 들어갔다.
4.1 Semantic Segmentation
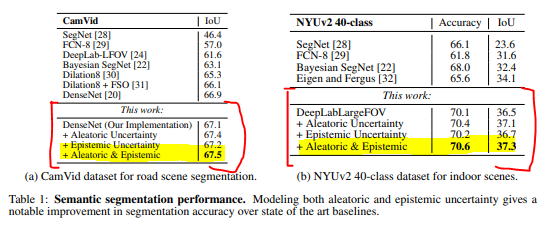
semantic segmentation에 대한 퍼포먼스 부분이다.
왼쪽 표는 CamVid 데이터, 오른쪽은 NYUv2 데이터로 진행한 결과를 나타낸 것이다.
왼쪽 표에서도 보이지만 기존의 성과를 뛰어 넘는 퍼포먼스를 보여줬다.
특히 여기서 우리가 알 수 있는 부분은 epistemic과 aleatoric uncertainty를 동시에 모델링에 적용했을 때 그 시너지 효과가 더 잘 나타난다는 것이다.
반면, 오른쪽 표를 보면 IoU가 왼쪽 CamVid보다 더 낮은 것으로 나오는데 그 이유를 데이터 셋이 더 어려운 데이터셋이라고 했다.
NYUv2 데이터에서는 DeepLabLargeFOV를 베이스 라인 모델로 설정하여 실험을 진행했다.
이 역시도 두 불확실성을 함께 모델링하니 성능이 더 좋아진 점을 확인 할 수 있다.
4.2 Pixel-wise Depth Regression
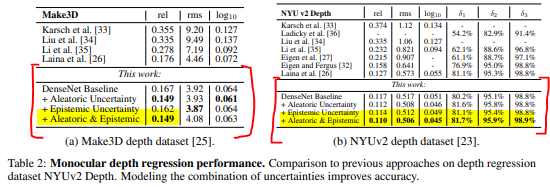
이번엔 regression 관련 퍼포먼스 부분이다.
본 실험에서는 Make3D와 NYUv2 Depth 데이터를 가지고 진행했다고 한다.
데이터에 대한 설명은 생략하지만, NYUv2 Depth 데이터는 위에서 semantic segmantation 실험에서 쓰였던 데이터와 동일하다.
이것이 가능한 이유는 RGB 값을 각각 갖는 이미지이기 때문이라고 한다.
그래서 이 데이터들로 어떻게 회귀와 관련된 실험을 하냐?
바로 monocular depth regression이라는 task이다.
이 것은 한 장의 사진으로부터 두 물체 사이의 거리를 재거나, 사진의 깊이를 구하는 과제로 쓰인다.
(참고: goodgodgd.github.io/ian-flow/archivers/hyu-jan-2020-lecture1)
본 연구로 알 수 있는 것은
Aleatoric uncertainty가 본질적으로 이미지에서 어느정도로 파악하기 어려운지를 캐치할 수 있는 지표가 될 수 있다는 것과
그로 인해서 데이터가 얼마나 부족한지를 epstemic uncertainty로 확인할 수 있다는 것이다.


